文本分类 原理篇
简单说就是根据我们的语料库,进行文本分类,常见的应用场景可能是情感分析、新闻分类、事件预测等等
1. 文本预处理#
英文文本预处理比较简单,直接按照空格切分即为一个个单词。中文则需要首先进行分词,将一个句子切分成一个个的词。
2. 文本特征提取#
即将文本的信息转为数值的信息,常见的方式有如下几种:
- 词袋模型:不关注单词在文档中出现的频次,只关注是否出现,即数值都是0、1
- CountVector:即word在文档中出现的频次
- TF-IDF模型
- 基于词向量word2vec
除此之外,还可以构造一些基于文本的统计类特征:
- 文档的词语计数—文档中词语的总数量
- 文档的词性计数—文档中词性的总数量
- 文档的平均字密度--文件中使用的单词的平均长度
- 完整文章中的标点符号出现次数--文档中标点符号的总数量
- 整篇文章中的大写次数—文档中大写单词的数量
- 完整文章中标题出现的次数—文档中适当的主题(标题)的总数量
- 词性标注的频率分布
- 名词数量
- 动词数量
- 形容词数量
- 副词数量
- 代词数量
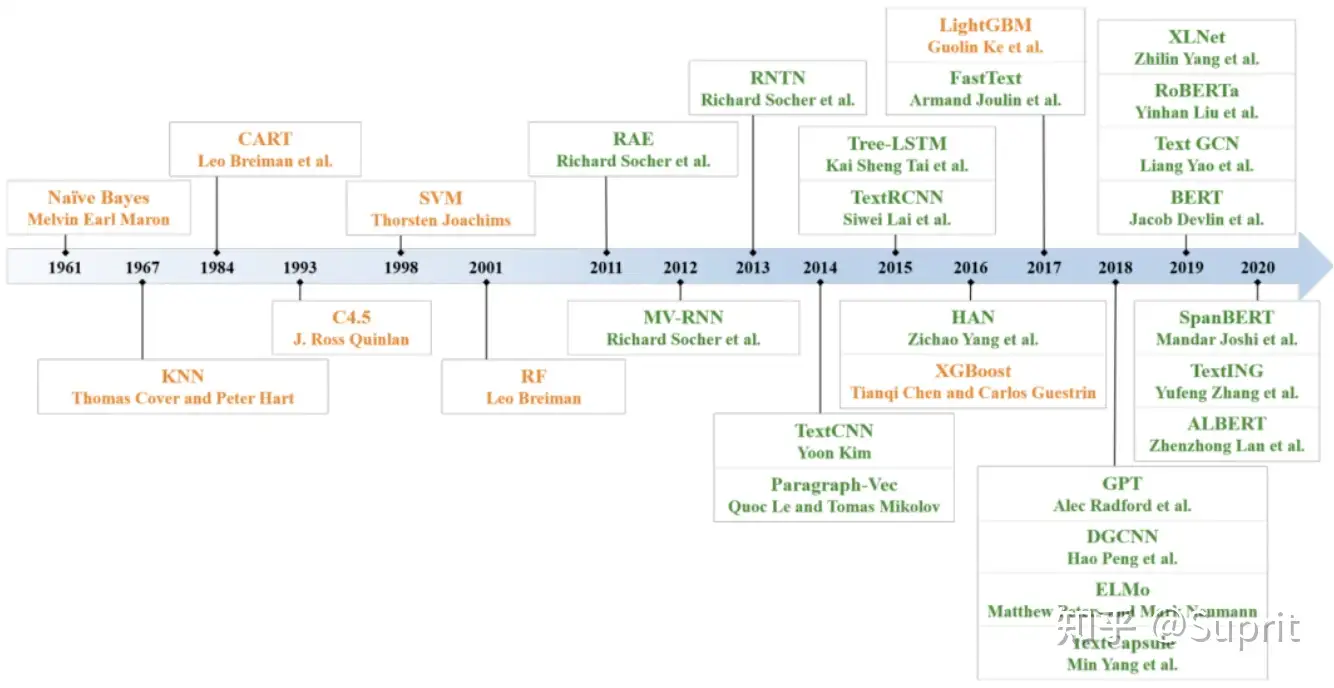
3. 训练模型#
传统模型
深度模型
参考#
https://zhuanlan.zhihu.com/p/436429409
案例
https://blog.csdn.net/u014281392/article/details/89972877
https://zhuanlan.zhihu.com/p/60532089
pyspark:
https://spark.apache.org/docs/3.3.2/ml-features.html#tf-idf